Amazon S3 is not the first cloud backup solution I’ve tried. I experimented with Glacier first. However, I know believe that if Glacier plays any part in my eventual cloub backup solution, it will be in conjunction with, not instead of, S3, so it makes sense to talk about S3 first.
A little context. I’m talking about backing up large amounts of data — I have about 6 TB — as part of what is sometimes called a hybrid backup system. In such a scheme, the main backup is onsite; the cloud portion is only for disaster recovery.
S3 works like most file-oriented cloud storage systems. You manage it from a web page. You can upload and download from a web page, too, but that’s probably not the way to implement a backup system, which should for the most part run unattended.
Amazon expects its users to write or purchase programs that access S3 rather than doing it all manually, and it makes provision to assign fine-grained permissions to those programs. First, you create a userid which is just used for one program. From a web browser, you ask Amazon to assign two keys to that userid: and Access Key ID, and Secret Access Key. You will only see the Secret Key once, and it’s really long. You enter both keys into your S3 client, and now it can access S3. But it can’t do anything yet.
Then you assign that user to a group and set access permissions for the group. Now your client can do whatever you decided to let it do, and no more. There ought to be a way to assign privileges directly to the userid and skip the assigning to a group; the Amazon Webs Services (AWS) GUI seems to let you do that. But I never was able to get the client working without assigning it to a group.
This complicated routine makes S3 access more secure than most cloud backup services, but also more cumbersome. You’ll notice that I haven’t mentioned two-factor security. It’s not that it’s unavailable, but I can’t figure out how to make it work for unattended operation. One security feature that would be welcome is the ability to restrict some kinds of access to certain IP addresses of groups of addresses. There may be a way to do that with S3, but I haven’t found it yet.
Goodsync, which I already use for onsite backup, has an S3 client mode. I set it up, pointed it at a directory with 70 GB of small and large files, analyzed, and did a partial backup. Then I reanalyzed:

Note that the analysis took more than an hour. That’s because Goodsync, even though it leaves a status file on the server side, doesn’t trust that file to be up to date. Instead it queries the S3 server about the contents of every folder. To make matters worse, even though S3 supports overlapping file operations, it does it sequentially.
When you actually do the file transfers, the combination of Goodsync and S3 can’t run faster than about 18 Mb/s. Here’s a look at the firewall’s traffic monitor with a series of medium-sized files:
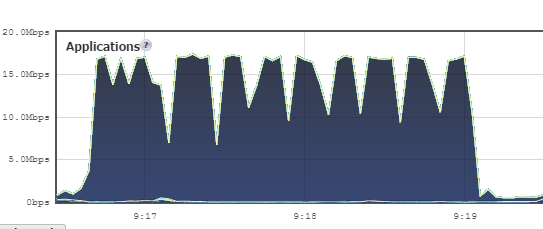
And with one big file:
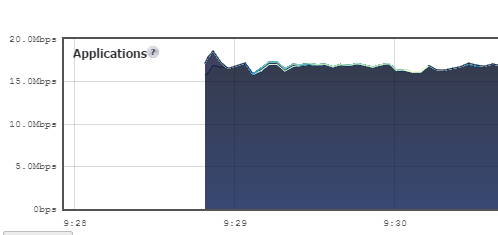
With small files, the Goodsync/S3 duo limps along like this:
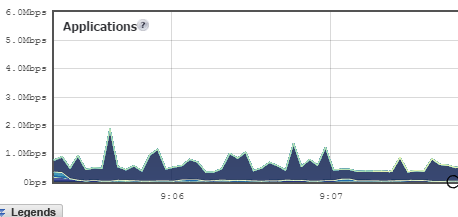
When the sync is over, we see that the average transfer rate is only about 8 Mb/s:

There are tools that take full advantage of S3’s concurrent file operations. Here’s one of them:
https://s3browser.com/s3-browser-free-vs-pro.php
However, this is not a complete unattended backup solution.
[…] S3 and GoodSync […]